最近苹果公司的研究团队和 Meta AI 的研究人员联合推出了一项名为 LazyLLM 的新技术,这项技术在提高大型语言模型(LLM)在长文本推理中的效率。
大家都知道,当前的 LLM 在处理长提示时,特别是在预充阶段,往往会面临速度慢的问题。这主要是因为现代的变换器架构在计算注意力时,其计算复杂度随着提示中的 token 数量呈平方关系增长。因此,在使用 Llama2模型时,首个 token 的计算时间往往是后续解码步骤的21倍,占据了生成时间的23%。
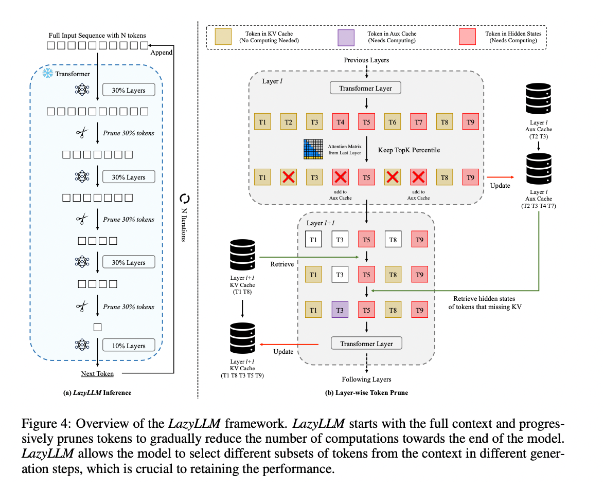
为了改善这一状况,研究者们提出 LazyLLM,这是一种通过动态选择重要 token 的计算方式来加速 LLM 推理的新方法。LazyLLM 的核心在于它会根据之前层的注意力分数评估每个 token 的重要性,从而逐步削减计算量。与永久性压缩不同的是,LazyLLM 可以在必要时恢复被削减的 token,以确保模型的准确性。此外,LazyLLM 引入了一种名为 Aux Cache 的机制,可以存储被剪枝 token 的隐含状态,从而高效地恢复这些 token,并防止性能下降。

LazyLLM 在推理速度上表现突出,尤其是在预填充和解码阶段。该技术的三个主要优点是:它与任何变换器基础的 LLM 兼容,实施过程中不需要进行模型的再训练,并且在多种语言任务上都表现得非常有效。LazyLLM 的动态剪枝策略使其在保留大部分重要 token 的同时,可以大幅度减少计算量,进而提升生成速度。
研究结果表明,LazyLLM 在多个语言任务上均表现优异,TTFT 速度提升达2.89倍(对于 Llama2)及4.77倍(对于 XGen),同时准确率几乎与基线持平。无论是问答、摘要生成还是代码补全任务,LazyLLM 都能实现更快的生成速度,并且在性能与速度之间取得良好的平衡。其渐进的剪枝策略加上逐层分析,为 LazyLLM 的成功奠定了基础。
论文地址:https://arxiv.org/abs/2407.14057
划重点:
🌟 LazyLLM 通过动态选择重要 token,加速 LLM 推理过程,特别是在长文本场景中表现突出。
⚡ 该技术能够显著提高推理速度,TTFT 速度提升可达4.77倍,同时保持较高的准确性。
🔧 LazyLLM 不需要对现有模型进行改动,可与任何变换器基础的 LLM 兼容,易于实施。
备注:资讯来源AIbase基地AiBase副业搞钱交流群
欢迎大家加入AiBase交流群, 扫码进入,畅谈AI赚钱心得,共享最新行业动态,发现潜在合作伙伴,迎接未来的赚钱机遇!。

